SQL의 윈도우 펑션기능을 소개합니다.
다행히도 엑셀팡션은 아닙니다.

진짜 시작
파티션함수의 형식
SELECT 집계함수([컬럼명]) OVER (PARTITION [컬럼명])
FROM 테이블명파티션 함수는 그룹별 집계, 순위 등을 구할 때 사용합니다.
그룹별 집계를 위해 예시 데이터를 만들고자 합니다.
Postgresql을 사용했습니다.
우선 아래와 같이 테이블을 만들어봅니다.
create table citizen (
id INT,
sex INT,
city varchar(100),
region INT,
primary key (id)
)데이터를 집어 넣습니다.
insert into citizen values(1,1,'서울',1)
insert into citizen values(2,2,'서울',1)
insert into citizen values(3,2,'서울',1)
insert into citizen values(4,2,'서울',1)
insert into citizen values(5,1,'서울',1)
insert into citizen values(6,2,'서울',2)
insert into citizen values(7,2,'서울',2)
insert into citizen values(8,2,'서울',2)
insert into citizen values(9,1,'서울',2)
insert into citizen values(10,1,'서울',2)
citizen테이블의 데이터를 전부 호출해봅니다.
select *
from citizen위와 같은 결과를 얻게 됩니다.
위 데이터를 성별에 따른 수를 집계한다면 어떻게 쿼리를 짤 수 있을까요?
윈도우 펑션을 쓰지 않는다면 group by를 통해서 아래와 같이 처리를 할 수 있습니다.
SELECT sex, COUNT(sex)
FROM citizen
GROUP BY sex그렇다면 그 결과는 아래와 같이 나올 것입니다.
성별 2로 표시된 것이 6개
성별 1로 표시된 것이 4개
인 것을 확인할 수 있습니다.
파티션 기능을 이용해서 성별에 따른 수를 집계한다면 어떻게 쿼리를 짤까요?
첫 번째 방법으로 이렇게 할 수 있을 것 같습니다.
select sex,
count(*) over(partition by sex) sex
from citizen그 결과는 아래와 같습니다.
10개의 관측치가 생성된 것을 확인할 수 있습니다.
읽는 법은 이렇습니다.
첫 번째 행의 경우 sex가 1로 표시된 것의 citizen 테이블 내 총 갯수는 4개,
두 번째 행의 경우 sex가 1로 표시된 것의 citizen 테이블 내 총 갯수는 4개,
세 번째 행의 경우 sex가 1로 표시된 것의 citizen 테이블 내 총 갯수는 4개,
네 번째 행의 경우 sex가 1로 표시된 것의 citizen 테이블 내 총 갯수는 4개,
다섯 번째 행의 경우 sex가 2로 표시된 것의 citizen 테이블 내 총 갯수는 총 갯수는 6개,
여섯 번째 행의 경우 sex가 2로 표시된 것의 citizen 테이블 내 총 갯수는 총 갯수는 6개,
일곱 번째 행의 경우 sex가 2로 표시된 것의 citizen 테이블 내 총 갯수는 총 갯수는 6개,
일곱 번째 행의 경우 sex가 2로 표시된 것의 citizen 테이블 내 총 갯수는 총 갯수는 6개,
일곱 번째 행의 경우 sex가 2로 표시된 것의 citizen 테이블 내 총 갯수는 총 갯수는 6개,
여덟 번째 행의 경우 sex가 2로 표시된 것의 citizen 테이블 내 총 갯수는 총 갯수는 6개,
아홉 번째 행의 경우 sex가 2로 표시된 것의 citizen 테이블 내 총 갯수는 총 갯수는 6개,
열 번째 행의 경우 sex가 2로 표시된 것의 citizen 테이블 내 총 갯수는 총 갯수는 6개
이렇듯 파티션 기능을 사용하면 테이블에 있는 동일 value의 갯수가 표시됩니다.
제 기준에서, 이렇게 보면 GROUP BY 를 쓴 것보다 좋은 점이 무엇인지 모르겠습니다.
파티션 기능은 장점은 아래와 같은 쿼리를 쓸 때 더 그 효과와 장점이 있는 것 같습니다.
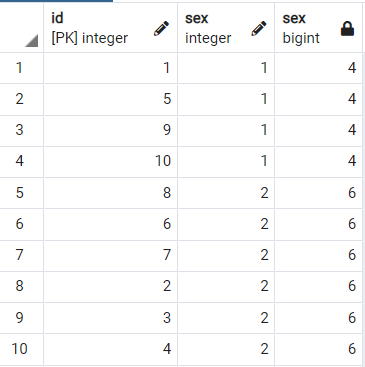
citizen의 아이디를 표시하고, 해당 아이디의 성별을 표시하고, 해당 성별이 전체 중 몇개를 차지하는지 보여주고 싶을 때 효과가 있습니다.
각 아이디별로 성별과, 성별의 집계, region과 region의 집계를 나타내고 싶은 경우 어떻게 할까요?
다시말해, 두 개의 컬럼을 기준잡아 집계하고 싶을 때 입니다.
그렇다면 아래와 같이 결과를 만들어낼 수 있습니다.
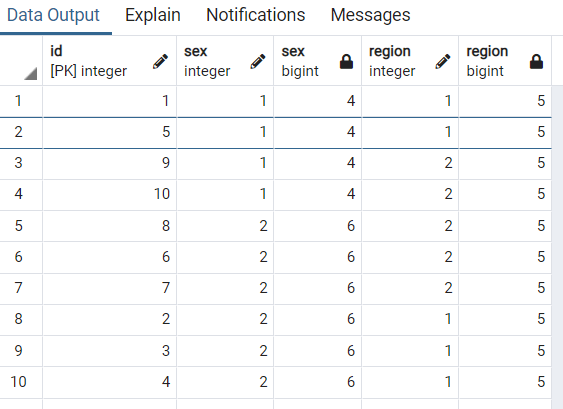
이러한 결과물은 어떻게 해석할까요?
id가 1인 주민의 경우, 성별은 1이고, 동일한 성별을 가진 시민의 수는 전체 table 내에서 4명 입니다.
또한 id가 1인 주민은 region이 1지역에 살고 있습니다. 1지역에 살고 있는 전체 시민 수는 5명입니다.
위와 같이 두 가지 이상의 기준을 가지고 그 계수를 집계할 때 유용합니다.
위와 같은 결과를 아래와 같은 코드를 이용했습니다.
select id, sex,
count(*) over(partition by sex) sex,
region,
count(*) over (partition by region) region
from citizen
id를 첫 열로 설정하고,
sex와 그 sex을 파티션으로 나누어 카운팅,
region과 그 region을 파티션으로 나누어 카운팅 했습니다.
'SQL ' 카테고리의 다른 글
| 조금 더 현실적인 문제 해결을 위한 SQL 쿼리 - 리팩토링 하기 (0) | 2022.01.03 |
|---|---|
| 조금 더 현실적인 문제 해결을 위한 SQL 쿼리짜기 (0) | 2021.12.19 |
| TestDome SQL리뷰 및 면접경험 (2) | 2021.12.08 |
| SUBSTRING(), REPLACE(), POSITION() and COALESE() (0) | 2021.04.23 |
| SQL 너 도대체 어떻게 공부 하는데...(경험을 중심으로) (0) | 2020.03.26 |


